
Gabriel Arpino
Postdoctoral Fellow · Harvard University & Yale University
I develop algorithms to make sense of high-dimensional data. My current work intersects with deep learning, distribution shifts, interpretability, and uncertainty quantification. Outcomes of my research include fast & accurate methods for non-stationary regression , and tight generalization bounds for deep learning .
I am a Postdoctoral Fellow jointly hosted by Subhabrata Sen at the Harvard University Department of Statistics, and by Theodor Misiakiewicz at the Yale University Department of Statistics and Data Science. I obtained my PhD from the University of Cambridge in 2025, advised by Ramji Venkataramanan and supported by the Cambridge Trust. I worked on Transformers for sea vessel track prediction as a Student Researcher at Google in 2025, and developed machine learning methods for the power grid as a Researcher at Invenia Labs in 2018.
Previously, I completed my Master's degree in EEIT at ETH Zürich, advised by Afonso Bandeira. Before that, I completed my undergraduate degree in Engineering Science at the University of Toronto, where I worked with Daniel Roy on deep learning generalization.
Selected Papers
* denotes equal contribution; αβ denotes alphabetical author ordering.

Abstract
We study the problem of identifying change points in high-dimensional generalized linear models, and propose an approach based on sample-weighted empirical risk minimization. Our method, Weighted ERM, encodes priors on the change points via weights assigned to each sample, to obtain weighted versions of standard estimators such as M-estimators and maximum-likelihood estimators. Under mild assumptions on the data, we obtain a precise asymptotic characterization of the performance of our method for general Gaussian designs, in the high-dimensional limit where the number of samples and covariate dimension grow proportionally. We show how this characterization can be used to efficiently construct a posterior distribution over change points. Numerical experiments on both simulated and real data illustrate the efficacy of Weighted ERM compared to existing approaches, demonstrating that sample weights constructed with weakly informative priors can yield accurate change point estimators. Our method is implemented as an open-source package, weightederm, available in Python and R.

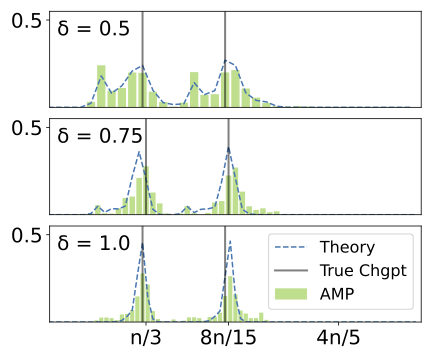
Abstract
We consider the problem of localizing change points in a generalized linear model (GLM), a model that covers many widely studied problems in statistical learning including linear, logistic, and rectified linear regression. We propose a novel and computationally efficient Approximate Message Passing (AMP) algorithm for estimating both the signals and the change point locations, and rigorously characterize its performance in the high-dimensional limit where the number of parameters p is proportional to the number of samples n. This characterization is in terms of a state evolution recursion, which allows us to precisely compute performance measures such as the asymptotic Hausdorff error of our change point estimates, and allows us to tailor the algorithm to take advantage of any prior structural information on the signals and change points. Moreover, we show how our AMP iterates can be used to efficiently compute a Bayesian posterior distribution over the change point locations in the high-dimensional limit. We validate our theory via numerical experiments, and demonstrate the favorable performance of our estimators on both synthetic and real data in the settings of linear, logistic, and rectified linear regression.

Abstract
We consider the problem of localizing change points in high-dimensional linear regression. We propose an Approximate Message Passing (AMP) algorithm for estimating both the signals and the change point locations. Assuming Gaussian covariates, we give an exact asymptotic characterization of its estimation performance in the limit where the number of samples grows proportionally to the signal dimension. Our algorithm can be tailored to exploit any prior information on the signal, noise, and change points. It also enables uncertainty quantification in the form of an efficiently computable approximate posterior distribution, whose asymptotic form we characterize exactly. We validate our theory via numerical experiments, and demonstrate the favorable performance of our estimators on both synthetic data and images.
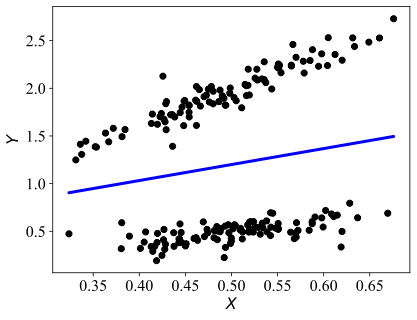
Abstract
We consider the problem of mixed sparse linear regression with two components, where two real k-sparse signals β1,β2 are to be recovered from n unlabelled noisy linear measurements. The sparsity is allowed to be sublinear in the dimension, and additive noise is assumed to be independent Gaussian with variance σ2. Prior work has shown that the problem suffers from a k/SNR^2-to-k^2/SNR^2 statistical-to-computational gap, resembling other computationally challenging high-dimensional inference problems such as Sparse PCA and Robust Sparse Mean Estimation; here SNR is the signal-to-noise ratio. We establish the existence of a more extensive computational barrier for this problem through the method of low-degree polynomials, but show that the problem is computationally hard only in a very narrow symmetric parameter regime. We identify a smooth information-computation tradeoff between the sample complexity n and runtime for any randomized algorithm in this hard regime. Via a simple reduction, this provides novel rigorous evidence for the existence of a computational barrier to solving exact support recovery in sparse phase retrieval with sample complexity n=õ(k2). Our second contribution is to analyze a simple thresholding algorithm which, outside of the narrow regime where the problem is hard, solves the associated mixed regression detection problem in O(np) time with square-root the number of samples and matches the sample complexity required for (non-mixed) sparse linear regression; this allows the recovery problem to be subsequently solved by state-of-the-art techniques from the dense case. As a special case of our results, we show that this simple algorithm is order-optimal among a large family of algorithms in solving exact signed support recovery in sparse linear regression.
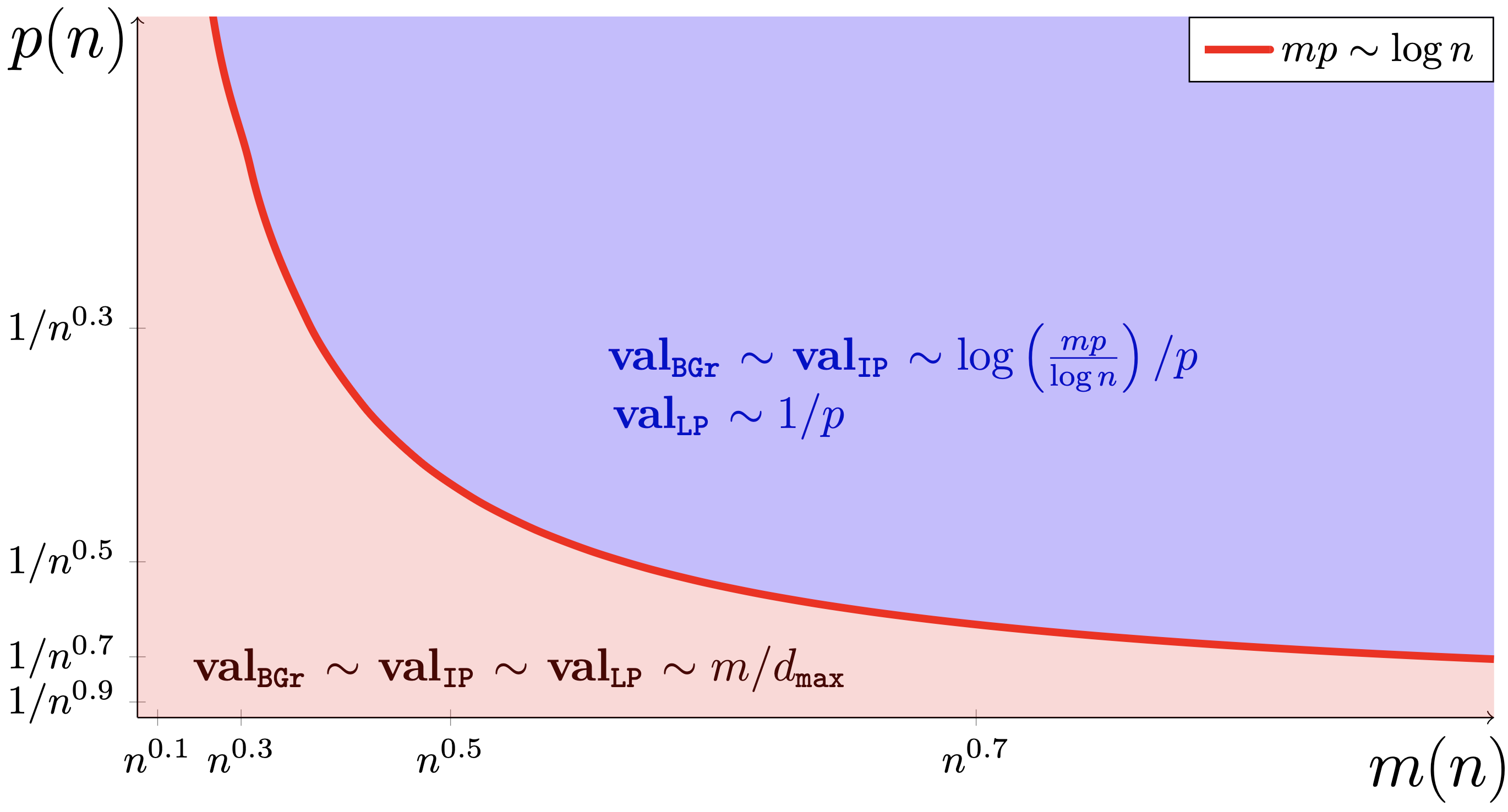
Abstract
Consider the Hitting Set problem where, for a given universe X={1,...,n} and a collection of subsets S1,...,Sm, one seeks to identify the smallest subset of X which has nonempty intersection with every element in the collection. We study a probabilistic formulation of this problem, where the underlying subsets are formed by including each element of the universe with probability p, independently of one another. For large enough values of n, we rigorously analyse the average case performance of Lovász's celebrated greedy algorithm (Lovász, 1975) with respect to the chosen input distribution. In addition, we study integrality gaps between linear programming and integer programming solutions of the problem.
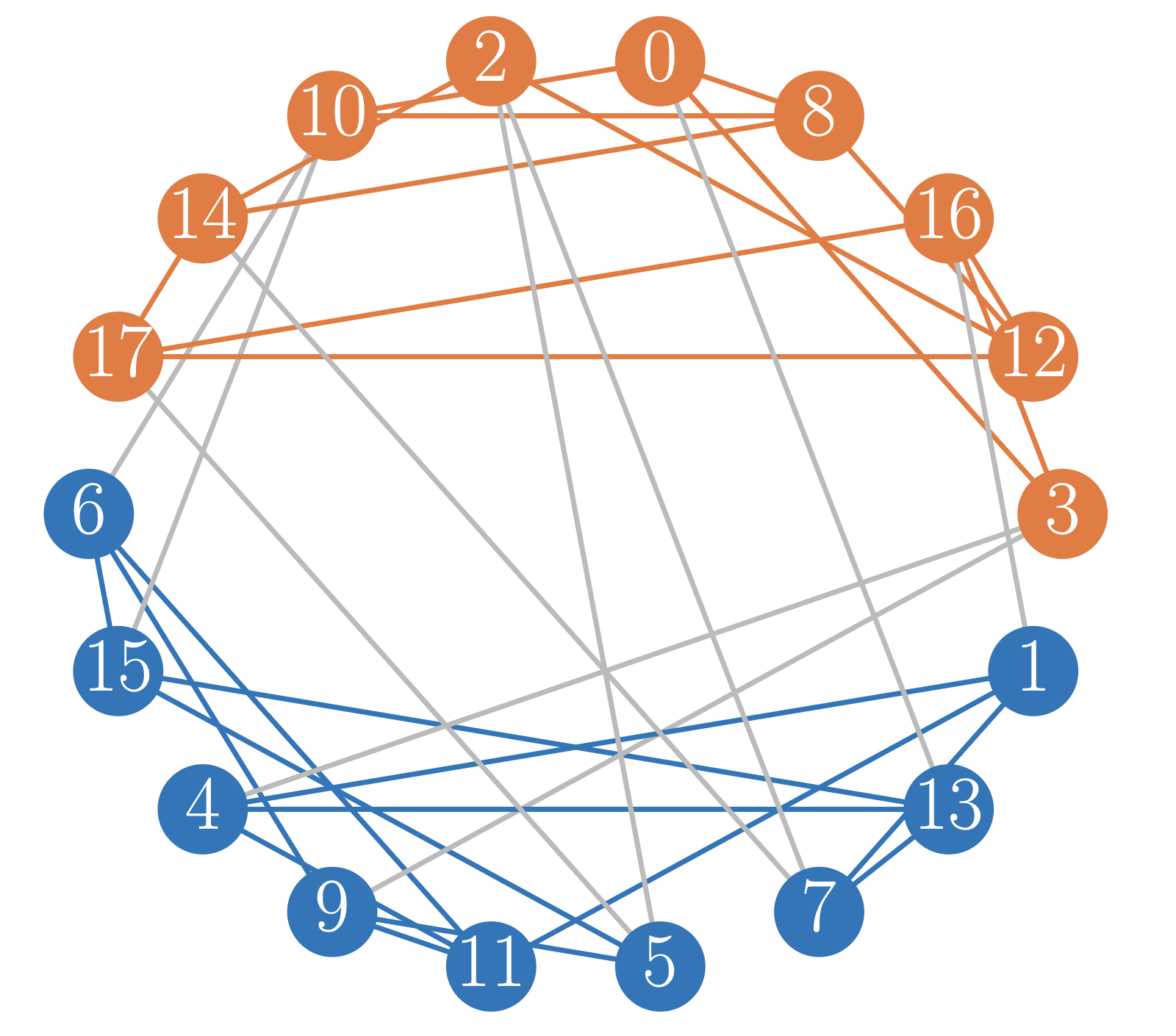
Abstract
We study the problem of assortative and disassortative partitions on random d-regular graphs. Nodes in the graph are partitioned into two non-empty groups. In the assortative partition every node requires at least H of their neighbors to be in their own group. In the disassortative partition they require less than H neighbors to be in their own group. Using the cavity method based on analysis of the belief propagation algorithm we establish for which combinations of parameters (d, H) these partitions exist with high probability and for which they do not. For H > d/2 we establish that the structure of solutions to the assortative partition problems corresponds to the so-called frozen-one-step replica symmetry breaking. This entails a conjecture of algorithmic hardness of finding these partitions efficiently. For H < d/2 we argue that the assortative partition problem is algorithmically easy on average for all d.
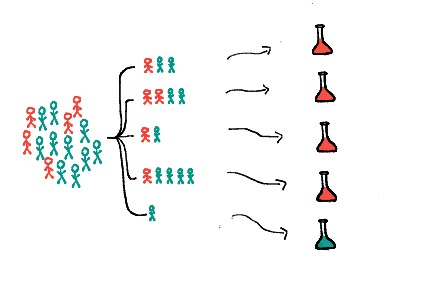
Abstract
Non-adaptive group testing refers to the problem of inferring a sparse set of defectives from a larger population using the minimum number of simultaneous pooled tests. Under the dilution noise model, items in a test pool have an i.i.d. probability of being diluted, meaning their contribution to a test does not take effect. In this setting, we investigate the number of tests required to achieve vanishing error probability with respect to existing algorithms and provide an algorithm-independent converse bound. In contrast to other noise models, we also encounter the interesting phenomenon that dilution noise on the resulting test outcomes can be offset by choosing a suitable noise-level-dependent Bernoulli test design, resulting in matching achievability and converse bounds up to order in the high noise regime.
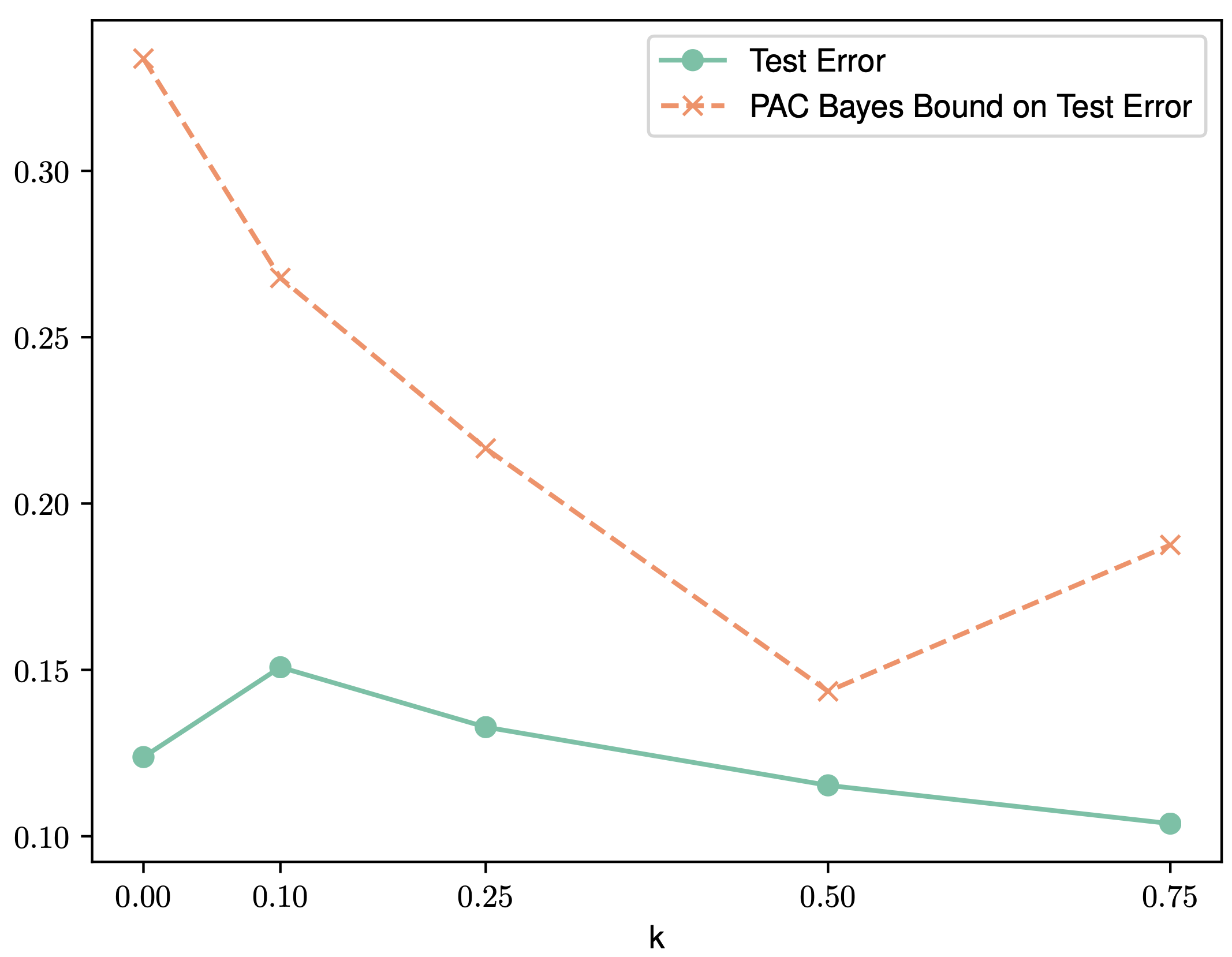
Abstract
The dominant term in PAC-Bayes bounds is often the Kullback–Leibler divergence between the posterior and prior. For so-called linear PAC-Bayes risk bounds based on the empirical risk of a fixed posterior kernel, it is possible to minimize the expected value of the bound by choosing the prior to be the expected posterior, which we call the oracle prior on the account that it is distribution dependent. In this work, we show that the bound based on the oracle prior can be suboptimal: In some cases, a stronger bound is obtained by using a data-dependent oracle prior, i.e., a conditional expectation of the posterior, given a subset of the training data that is then excluded from the empirical risk term. While using data to learn a prior is a known heuristic, its essential role in optimal bounds is new. In fact, we show that using data can mean the difference between vacuous and nonvacuous bounds.

Abstract
Robotic swarms are decentralized multi-robot systems whose members use local information from proximal neighbors to execute simple reactive control laws that result in emergent collective behaviors. In contrast, members of a general multi-robot system may have access to global information, all- to-all communication or sophisticated deliberative collaboration. Some algorithms in the literature are applicable to robotic swarms. Others require the extra complexity of general multi- robot systems. Given an application domain, a system designer or supervisory operator must choose an appropriate system or algorithm respectively that will enable them to achieve their goals while satisfying mission constraints (e.g. bandwidth, energy, time limits). In this paper, we compare representative swarm and general multi-robot algorithms in two application domains - navigation and dynamic area coverage - with respect to several metrics (e.g. completion time, distance trav- elled). Our objective is to characterize each class of algorithms to inform offline system design decisions by engineers or online algorithm selection decisions by supervisory operators. Our contributions are (a) an empirical performance comparison of representative swarm and general multi-robot algorithms in two application domains, (b) a comparative analysis of the algorithms based on the theory of information invariants, which provides a theoretical characterization supported by our empirical results.
Invited Talks & Presentations
Software
Contact
gabrielarpino at fas dot harvard dot edu
swap “at”/“dot” for the symbols.